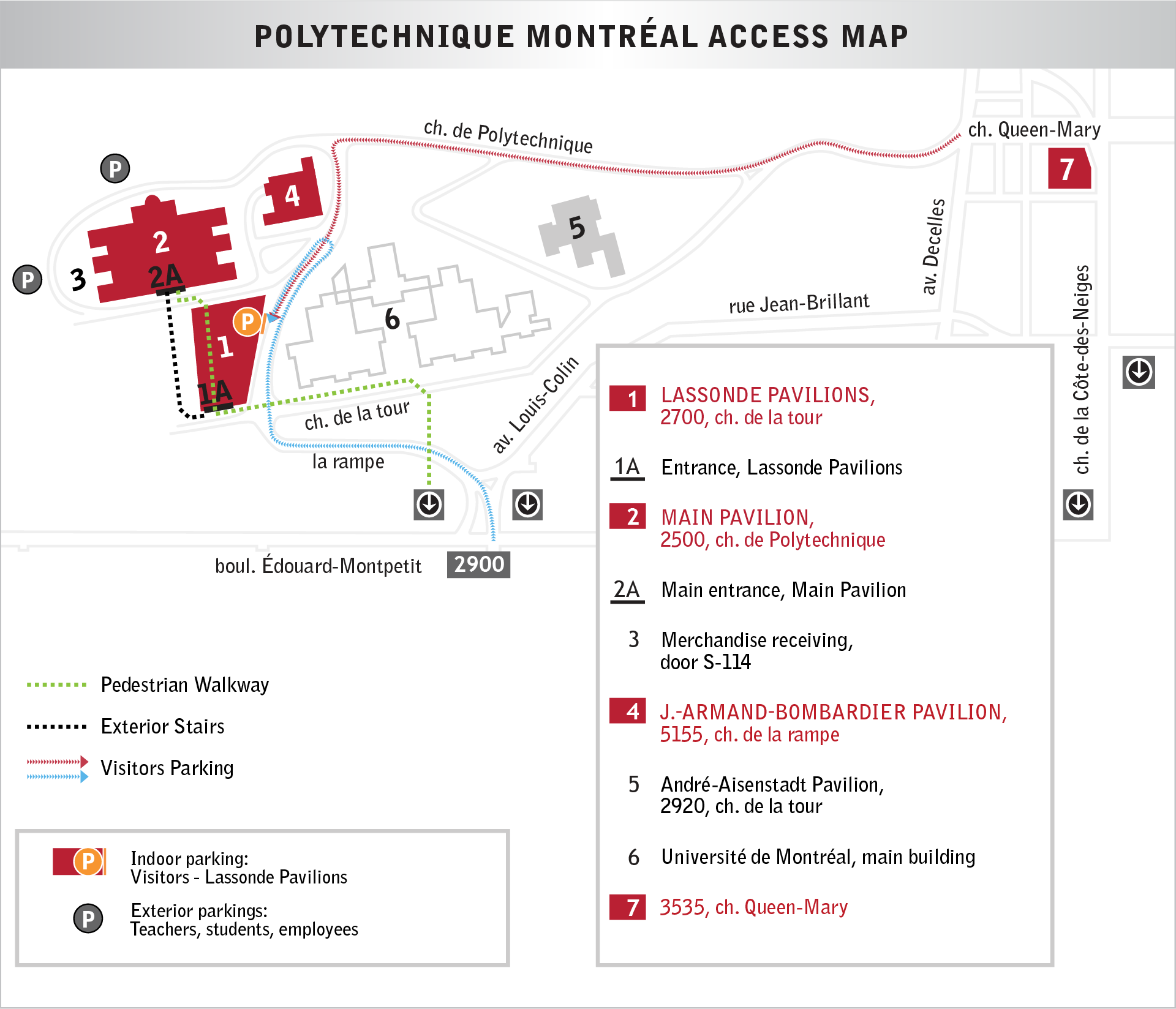
A meeting of the SEMTL community will be held on Thursday, June 19th, 2025, starting at 09:00. It will take place at Polytechnique Montréal, room A-416 in the Pavilion Principale (see map below). Coffee and pastries will be available during the meeting.
This edition of SEMTL takes place during the third day of the Software Engineering for Machine Learning Applications (SEMLA) symposium.
Registration
Please RSVP using this form.
Note that you do not have to register for SEMLA to attend SEMTL.
Program
-
08:30 - Coffee and pastries
-
09:00 - Welcome message
- 09:05 - Keynote - Julien Cohen-Adad - An (Un)Success-Story in the Development of Software for AI and Medical Imaging
- Affliations: Polytechnique Montréal, UdeM, Mila, CRIUGM, Canada Research Chair in quantitative MRI
- Abstract: In this presentation, Julien Cohen-Adad shares lessons learned from developing software for AI in medical imaging, focusing on the challenges of generalizing deep learning models across diverse clinical settings. He outlines key limitations in neuroimaging AI, such as small datasets, limited annotations, and lack of robustness across imaging contrasts and sites. Strategies to address these issues include domain adaptation, multi-contrast training, and injecting MR physics priors into model architectures. While some successes emerged—like improved tumor segmentation—many approaches faced limitations, especially in the face of inter-rater variability. Julien then reflects on the development and eventual sunsetting of some medical AI software framework, advocating instead for lighter, more maintainable tools, leveraging open standards like BIDS and popular ecosystems like MONAI. The talk concludes with a call for reproducible research, practical innovation, and leveraging local strengths—such as MR physics knowledge and clinical collaborations—rather than competing with industry-scale AI.
- 10:00 - Lina Marsso - Toward Trustworthy AI-Based Systems
- Affliation: Polytechnique Montréal
- Abstract: In this talk, I will show how we can integrate formal methods with software engineering techniques to build trustworthy autonomous systems. My work and research vision have three objectives: (1) specify what trustworthiness means for autonomous systems; (2) validate systems against those specifications; and (3) enable self-adaptation so that systems evolve until they satisfy the specifications.
- 10:25 - Lightning talks - 3 minutes each
- Towards Reliable and Trustworthy AI Systems in Software Engineering: A Literature Review on Miscommunication in Human-AI Interaction - Huizi Hao, Queen’s University
- CodeChat: A Large Dataset of Conversations Between Programmers and Large Language Models for Understanding Use Cases and Code Quality Issues - Suzhen Zhong, Queen’s University
- LLMs for Public Sector Compliance: Automating BABA Reviews with BERT and LLaMA - Qadri H Shaheen, University of Maryland
- AI-Driven Bidding Decisions: Enhancing Competitive Construction Strategies with Machine Learning - Qadri H Shaheen, University of Maryland
- DoomArena: A framework for Testing AI Agents Against Evolving Security Threats - Léo Boisvert, MILA, Polytechnique Montréal, ServiceNow Research
-
10:40 - Coffee break
- 11:00 - Lili Wei - How Far are Android App Secrets from Being Stolen?
- Affliation: McGill University
- Abstract: Android apps hold secret strings of themselves such as cloud service credentials or encryption keys. Leakage of such secret strings can induce unprecedented consequences like monetary losses or leakage of user private information. In this talk, I will introduce our recent work on characterizing app secrets that are checked in the released app package files. Our study shows that exploitable app secrets can be harvested with nothing more than simple regular expressions.
- 11:25 - Amine Mhedhbi - Towards Multimodal Database Management Systems
- Affliation: Polytechnique Montréal
- Abstract: As language models become widely accessible, organizations are investing in software systems that retrieve and reason over large, semantically rich data for scientific and business workflows. These data sources are often heterogeneous and multimodal. Approximately 80% of enterprise data is unstructured, and much of it remains untapped. Despite growing investment, implementing these workflows remains engineering-heavy and costly, requiring specialized expertise. Developers are forced to make many low-level execution decisions and rely on loosely coupled systems connected by hand-written orchestration scripts. This hinders adoption, especially among small and medium-sized enterprises and government agencies. To address these challenges, I believe a new class of data systems is needed: multimodal database management systems (DBMSes). These data systems would tightly fuse analytics with AI-integrated prediction and reasoning. They will sit atop repositories of raw data spanning tables, documents, images, and audio. In this talk, I focus on giving a broad overview of the needed capabilities and the research challenges towards making multimodal DBMSes mature and usable.
- 11:50 - Houssem Ben Braiek, Ahmed Haj Yahmed, and Foutse Khomh – VerifIA: Open-source Domain-Aware Verification Tool
- Affliation: Syscodal and Polytechnique Montréal
- Abstract: This talk introduces VerifIA, an open-source, domain-aware verification framework that evaluates AI models in the staging phase—after they clear data-driven benchmarks but before deployment. At this stage, models must still align with application-specific domain knowledge. VerifIA’s inaugural release automates a battery of rule-based and search-driven verifications—covering in-domain input space—to expose brittle behaviours and inconsistencies that statistical tests miss. It then generates an interactive validation report, linked to the staging model, that equips Ops teams with clear evidence for deploy-or-iterate decisions. Built-in adapters load models from scikit-learn, LightGBM, CatBoost, XGBoost, PyTorch, and TensorFlow, and push HTML reports directly to MLflow, Comet ML, or Weights & Biases for one-click go/no-go approval. A retrieval-augmented, human-in-the-loop flow drafts domain rules automatically and lets experts refine them, trimming setup time from days to minutes. The session unpacks VerifIA’s Arrange–Act–Assert workflow, presents a live demo, and showcases end-to-end use cases—providing a practical blueprint for ensuring forecasting models in production meet domain standards and application requirements.
- 12:15 - Lightning talks - 3 minutes each
- Beyond Quacking: Deep Integration of Language Models and RAG into DuckDB - Anas Dorbani, Polytechnique Montréal
- MonoEmbed: LLM Representations for Monolith-to-Microservice Decomposition - Khaled Sellami, Université Laval
- Extracting Microservices from Monolithic Systems using Deep RL - Khaled Sellami, Université Laval
- Unveiling Kubernetes Misconfigurations: Empirical Analysis and Improved Detection Approaches for Cloud-Native Infrastructures - Mostafa Anouar Ghorab, Université Laval
- Online Self-Supervised Multimodal Vision Transformers for First-Person Human Action Recognition - Armin Nabaei, Université de Sherbrooke
- 12:30 - Social event
- For the social event, we will eat lunch with all SEMLA attendees
- If you are registered for SEMLA, then lunch is provided.
- Otherwise, please bring a lunch, or there is a (good) cafeteria available
- Starting at 13:30 - Tutorials
- SEMTL attendees are warmly invited to attend the hands-on tutorials taking place at SEMLA (for free, no registration required)
- Please see https://semla.polymtl.ca/tutorials/ for the details
- Hands-on Tutorial on Quantum Software Engineering and Research
- From Metrics to Misbehavior: Hands-on with Dynamic Evaluation of LLM Code Generation
- Search-Based Test Generation for Autonomous Systems: From Fuzzing to Surrogate-Guided Optimization
- What is a “Digital Twin” and How Do I Build One?
Localisation
Easily accessible from the University de Montréal station on the blue metro line.
Polytechnique Montréal
2500 chemin de Polytechnique
We will be in the building marked ‘2’ on this map: